DB에서 인덱스를 사용하면 검색이 빨라진다 라는 말은 들어왔지만 어떻게 써야 효율적으로 동작하고, 인덱스는 어떠한 과정을 거치길래 빨라지는지에 대해서는 생각해본 적이 없는 듯 하다.
그래서 이번 포스팅에선 PostgreSQL를 가지고 INDEX를 사용하며 INDEX를 사용하며 얻을 수 있는 이점들에 대해 알아보고자 한다.
아래의 내용에 대해 다루어 본다.
- Index 적용 전 후의 수행시간 비교
- Multi Column Index에 대해서 사용
인덱스는 따로 파일로 저장하여 테이블 레코드를 전체 스캔하는게 아닌, 따로 파일로 저장된 INDEX 파일을 검색하여 속도를 개선한다. 이때 B-tree를 이용한다.
초기 테이블 생성할때 만들어지는 MYD, MYI, FRM 파일 중에서 인덱스를 특정 컬럼에 부여하면 이 파일들 중 MYI파일에 내용을 입력하게 된다.
이후부터 TREE 구조의 데이터에서 검색을 행하게 된다.
인덱스의 속도와 관련해 쿼리를 실행하며 비교해보자
people 이라는 테이블을 생성한다. 해당 테이블에는 id, first_name, last_name 에 대한 컬럼을 가지고 있다.
CREATE TABLE people (
id integer PRIMARY KEY,
first_name varchar(50),
last_name varchar(50)
);기본 키(primary key)에 대해서는 인덱스가 자동으로 생성된다.
이를 직접 확인해보고자 pg_indexes 를 통해 해당 내용을 찾아보았다.
db=# select * from pg_indexes where tablename = 'people';
schemaname | tablename | indexname | tablespace | indexdef
------------+-----------+-------------+------------+-------------------------------------------------------------------
public | people | people_pkey | | CREATE UNIQUE INDEX people_pkey ON public.people USING btree (id)
(1 row)
이론과 그대로, B-TREE를 이용해 인덱스를 찾음을 알 수 있었다.
인덱스를 이용한 수행 시간 비교에 앞서, people 테이블에 들어가는 row를 10,000 개로 INSERT 해본다
Script-to-load-10000-names.txt 파일을 사용하여 정보를 넣었다.
위 링크는 비공개 처리가 되어 아래 CSV 파일을 통해 person 을 정의한 정보를 대체하여 얻을 수 있다.
https://www.postgresqltutorial.com/wp-content/uploads/2020/07/persons.csv
last_name이 Ingram인 사용자에 대해 조회해본다.
db=# explain ANALYSE select * from people where last_name = 'Ingram';
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on people (cost=0.00..186.00 rows=18 width=17) (actual time=0.126..1.056 rows=21 loops=1)
Filter: ((last_name)::text = 'Ingram'::text)
Rows Removed by Filter: 9979
Planning Time: 0.094 ms
Execution Time: 1.091 ms
(5 rows)순차적으로 스캔 함을 확인할 수 있고, 수행시간은 1.091ms 가 소요되었다.
(explain analyse는 해당 쿼리에 대해 구문 실행계획과 소요 비용, 소요 시간에 대한 정보를 제공한다)
이제 인덱스를 이용해서 SELECT 쿼리를 수행해보자
index_people_names 라는 이름으로 people 테이블에 last_name 컬럼에 대하여 인덱스를 생성하였다.
db=# create index index_people_names on people (last_name);
CREATE INDEX
인덱스가 생성됨을 다시 확인해본다.
db=# select * from pg_indexes where tablename = 'people';
schemaname | tablename | indexname | tablespace | indexdef
------------+-----------+--------------------+------------+--------------------------------------------------------------------------
public | people | people_pkey | | CREATE UNIQUE INDEX people_pkey ON public.people USING btree (id)
public | people | index_people_names | | CREATE INDEX index_people_names ON public.people USING btree (last_name)
(2 rows)
다시 last_name이 Ingram인 사용자에 대해 조회해본다.
db=# explain analyse select * from people where last_name = 'Ingram';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on people (cost=4.42..44.07 rows=18 width=17) (actual time=0.042..0.075 rows=21 loops=1)
Recheck Cond: ((last_name)::text = 'Ingram'::text)
Heap Blocks: exact=17
-> Bitmap Index Scan on index_people_names (cost=0.00..4.42 rows=18 width=0) (actual time=0.032..0.032 rows=21 loops=1)
Index Cond: ((last_name)::text = 'Ingram'::text)
Planning Time: 0.130 ms
Execution Time: 0.121 ms
(7 rows)Seq Scan이 아닌, Bitmap Heap Scan 으로 실행이 되며
Seq Scan일때 Execution Time: 1.091 ms 인데 반해 인덱스를 사용하면서 Execution Time: 0.121 ms 로 줄어듦을 볼 수 있다.
이제 Multi Column Index에 대해서 알아보자
Multi Column Index
위의 인덱스 생성에서는 컬럼을 1개로만 두었다.
멀티 컬럼 인덱스를 사용하면 컬럼을 2개 이상으로 지정할 수 있다. (32개의 컬럼이 제한이라고 함)
멀티 컬럼 인덱스에서 유의해야 할 점은 인덱스 생성 시에 명시한 컬럼의 좌측 부터 사용해야 인덱스 이용이 가능하다.
먼저 기존에 생성했던 인덱스를 제거하고 새로 만들어본다.
db=# drop index index_people_names;
DROP INDEX
db=# create index index_people_names on people (last_name, first_name);
CREATE INDEX
last_name으로 Ingram, first_name은 Alice로 두고 탐색을 해보자
db=# explain analyse select * from people where last_name = 'Ingram' and first_name = 'Alice';
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Index Scan using index_people_names on people (cost=0.29..8.30 rows=1 width=17) (actual time=0.034..0.038 rows=2 loops=1)
Index Cond: (((last_name)::text = 'Ingram'::text) AND ((first_name)::text = 'Alice'::text))
Planning Time: 0.158 ms
Execution Time: 0.075 ms
(4 rows)Index Scan으로 실행 됨을 확인하였다.
인덱스 생성시 가장 왼쪽의 컬럼명인 last_name 만 둔 상태에서도 인덱스를 통해 검색이 가능하다.
그러나, 아래의 경우에선 Index Scan이 아닌, Bitmap Heap Scan으로 동작하게 된다.
db=# explain analyse select * from people where last_name = 'Ingram';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on people (cost=4.42..44.07 rows=18 width=17) (actual time=0.048..0.075 rows=21 loops=1)
Recheck Cond: ((last_name)::text = 'Ingram'::text)
Heap Blocks: exact=17
-> Bitmap Index Scan on index_people_names (cost=0.00..4.42 rows=18 width=0) (actual time=0.038..0.038 rows=21 loops=1)
Index Cond: ((last_name)::text = 'Ingram'::text)
Planning Time: 0.188 ms
Execution Time: 0.135 ms
(7 rows)위와 같은 이유는 last_name이 Ingram인 경우에 해당하는 Row 개수가 21개 이다.
인덱스 스캔은 너무 많아 효율성이 떨어지고, 순차적인 스캔을 하기엔 적은 경우 Bitmap Heap Scan으로 동작한다.
아래와 같은 방법으로 스캔이 처리된다
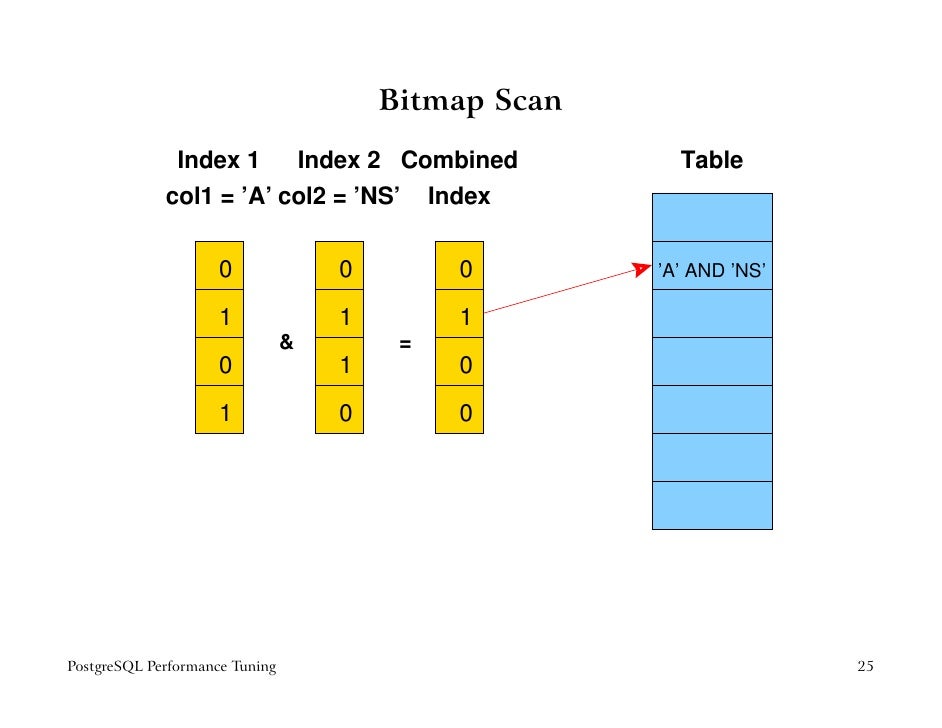
참고-postgresql performance tuning
인덱스에서의 좌측 컬럼부터 사용하지 않는 경우엔 인덱스 사용이 되지 않음을 볼 수 있다.
db=# explain analyse select * from people where first_name = 'Alice';
QUERY PLAN
-----------------------------------------------------------------------------------------------------
Seq Scan on people (cost=0.00..186.00 rows=27 width=17) (actual time=0.060..1.075 rows=27 loops=1)
Filter: ((first_name)::text = 'Alice'::text)
Rows Removed by Filter: 9973
Planning Time: 0.515 ms
Execution Time: 1.102 ms
(5 rows)
댓글